
Building effective agents
Building effective agents
转载说明
该篇文章对2024年大模型领域的实际落地场景做了一个很好的总结,给出了一些可行的落地思路参考.
原文地址: https://www.anthropic.com/research/building-effective-agents
Over the past year, we’ve worked with dozens of teams
In this post, we
What are agents?
“Agent” can be
Workflows are systems where LLMs and tools are
orchestrated through predefined code paths .Agents, on the other hand, are systems where LLMs
dynamically direct their own processes and tool usage,maintaining control over how they accomplish tasks .
Below, we will
When (and when not) to use agents
When
When more complexity is
When and how to use frameworks
There are many
- LangGraph from LangChain;
- Amazon Bedrock’s AI Agent framework;
- Rivet, a drag and drop GUI LLM
workflow builder ; and - Vellum, another GUI tool for building and testing
complex workflows .
These frameworks make it easy to get started bysimplifying standard low-level tasks likecalling LLMs ,defining and parsing tools , andchaining calls together . However, they often create extra layers ofabstraction that canobscure the underlying prompts and responses , making them harder todebug . They can also make ittempting to add complexity when a simplersetup wouldsuffice .
We suggest that developers start by using LLM APIs directly: many
See our cookbook for some sample
Building blocks, workflows, and agents
In this section, we’ll
Building block: The augmented LLM
The 
We recommend
For the remainder of this post, we’ll
Workflow: Prompt chaining
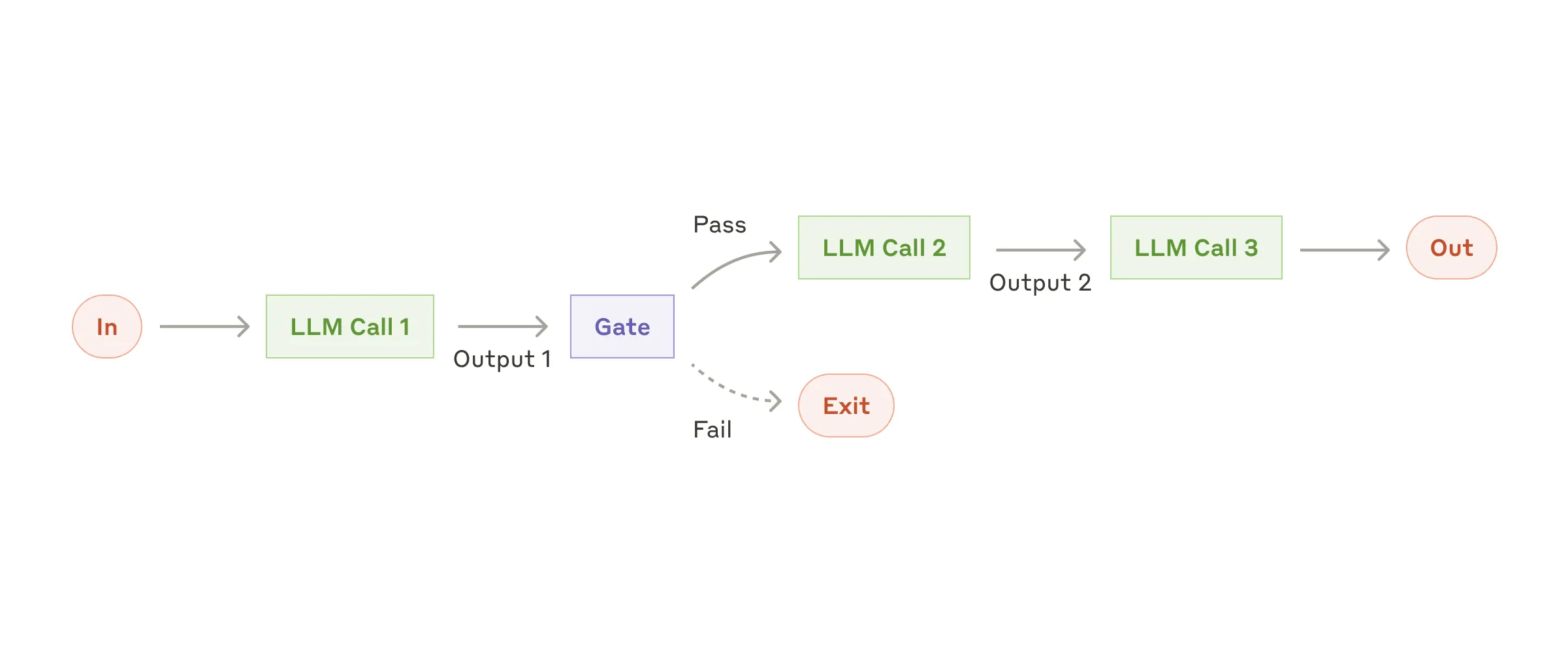
When to use this workflow: This workflow is
Examples where prompt chaining is useful:
Generating Marketing copy, then translating it into a different language .Writing an outline of a document, checking that the outline meets certain criteria, then writing the document based on the outline .
Workflow: Routing
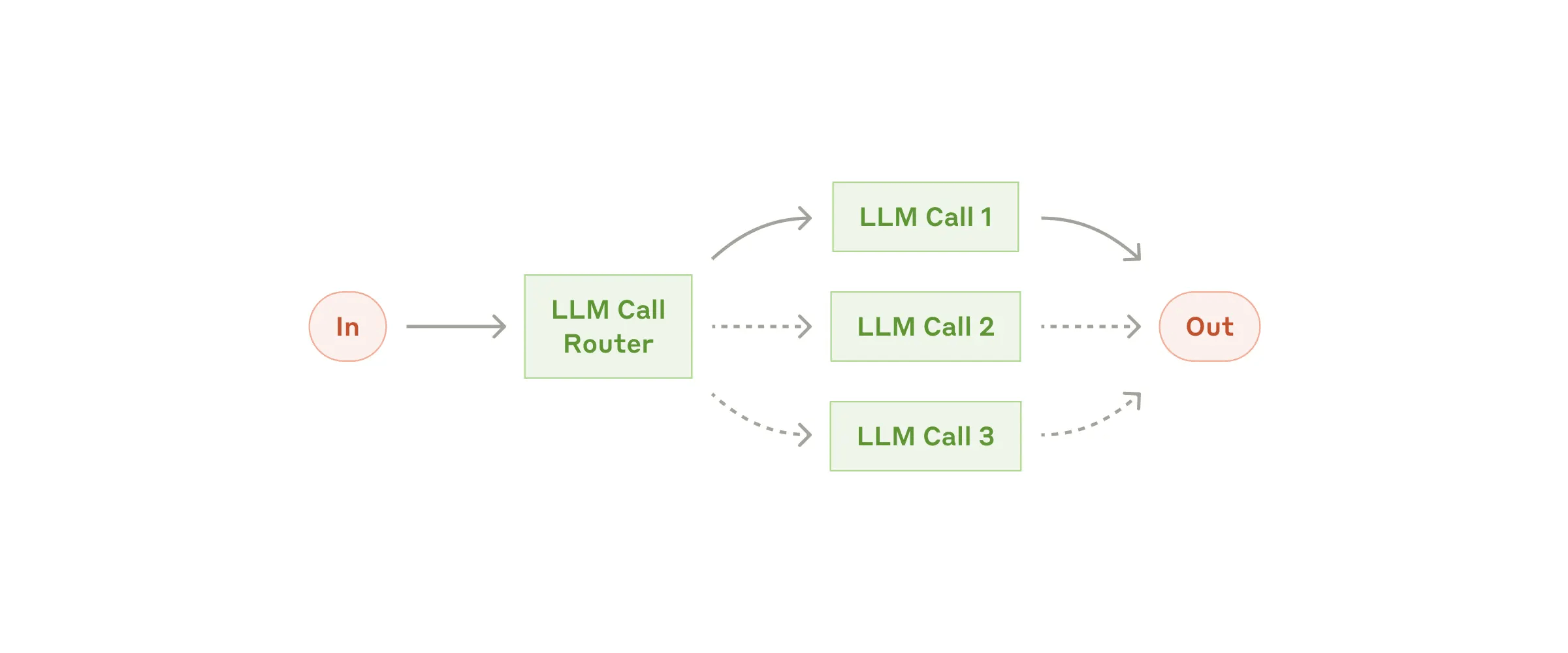
When to use this workflow: Routing works well for
Examples where routing is useful:
Directing different types of customer service queries (general questions, refund requests, technical support) into different downstream processes, prompts, and tools .Routing easy/common questions to smaller models like Claude 3.5 Haiku and hard/unusual questions to more capable models like Claude 3.5 Sonnet to optimize cost and speed .
Workflow: Parallelization
LLMs can sometimes work simultaneously on a task and have their outputs
Sectioning :Breaking a task into independent subtasks run in parallel .Voting :Running the same task multiple times to get diverse outputs .
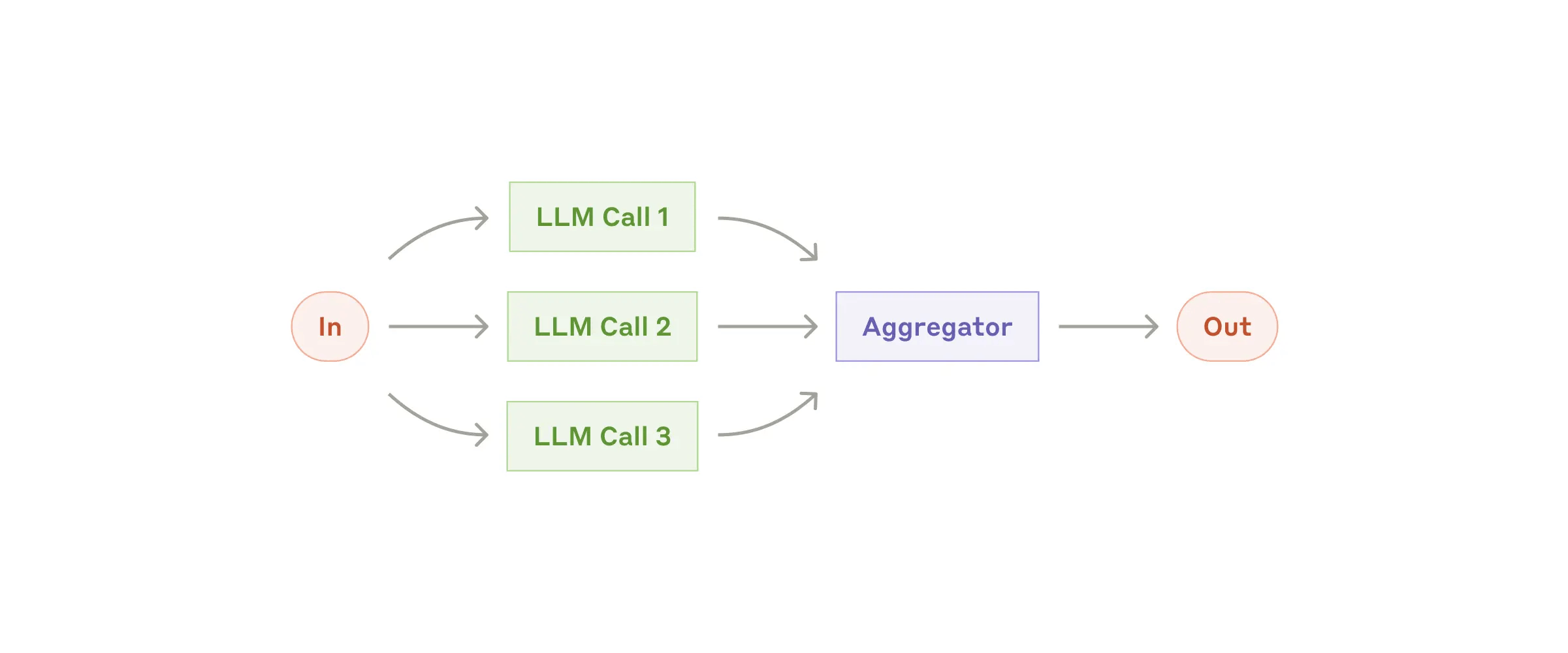
When to use this workflow:
Examples where parallelization is useful:
- Sectioning:
Implementing guardrails where one model instance processes user queries while another screens them for inappropriate content or requests. This tends to perform better than having the same LLM call handle both guardrails and the core response .Automating evals for evaluating LLM performance, where each LLM call evaluates a different aspect of the model’s performance on a given prompt .
- Voting:
Reviewing a piece of code for vulnerabilities, where several different prompts review and flag the code if they find a problem .Evaluating whether a given piece of content is inappropriate, with multiple prompts evaluating different aspects or requiring different vote thresholds to balance false positives and negatives .
Workflow: Orchestrator-workers
In the
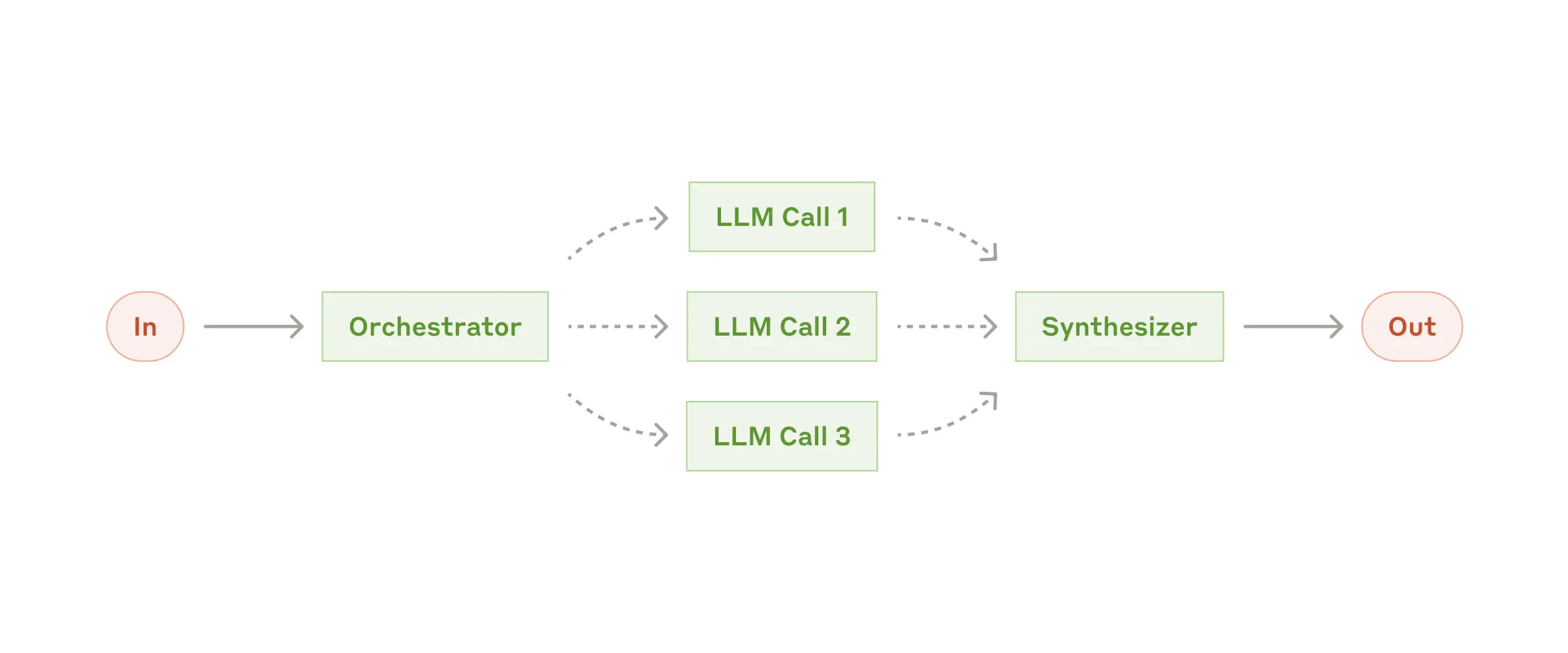
When to use this workflow: This workflow is
Example where
Coding products that make complex changes to multiple files each time .Search tasks that involve gathering and analyzing information from multiple sources for possible relevant information .
Workflow: Evaluator-optimizer
In the

When to use this workflow: This workflow is
Examples where
Literary translation where there are nuances that the translator LLM might not capture initially, but where an evaluator LLM can provide useful critiques .Complex search tasks that require multiple rounds of searching and analysis to gather comprehensive information, where the evaluator decides whether further searches are warranted .
Agents
Agents can handle
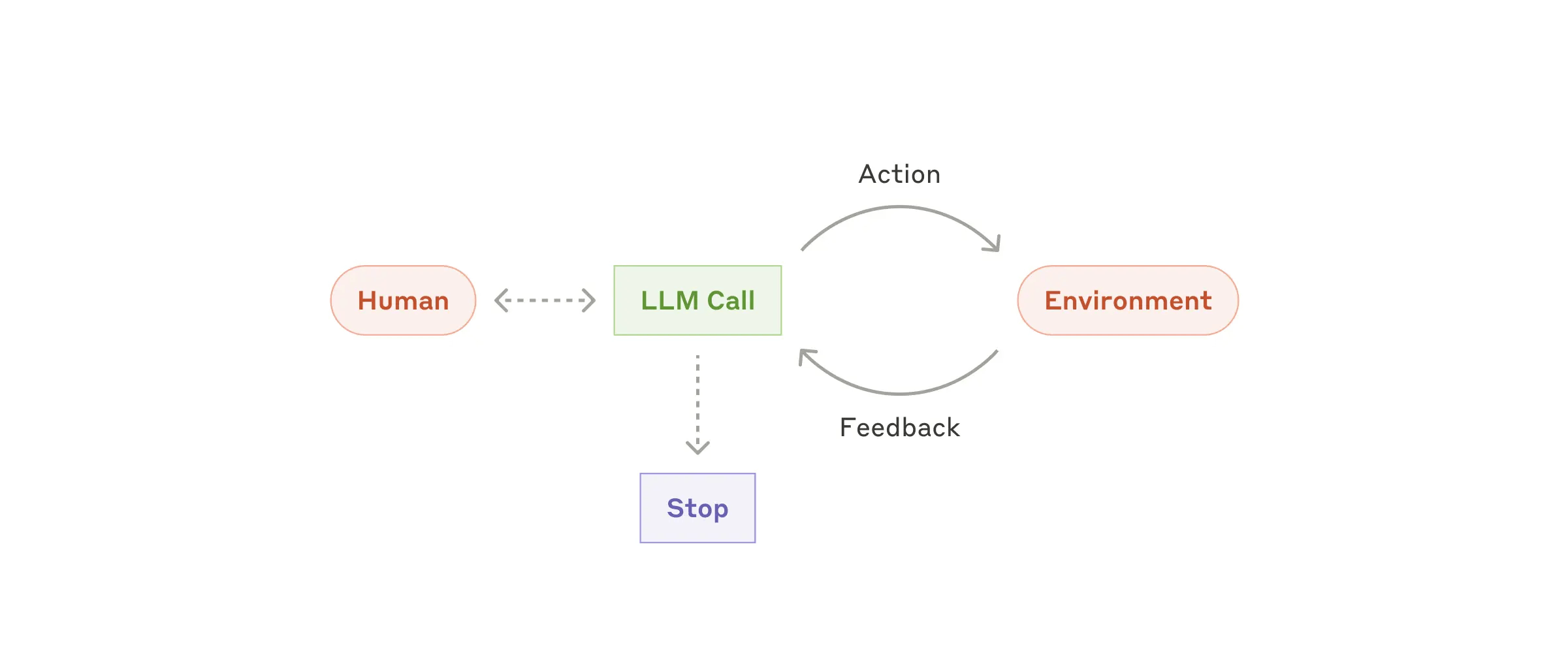
When to use agents: Agents can be used for
The
Examples where agents are useful:
The following examples are from our own implementations:
- A coding Agent to
resolve SWE-bench tasks , which involve edits to many files based on a task description; - Our “computer use” reference implementation, where Claude uses a computer to accomplish tasks.
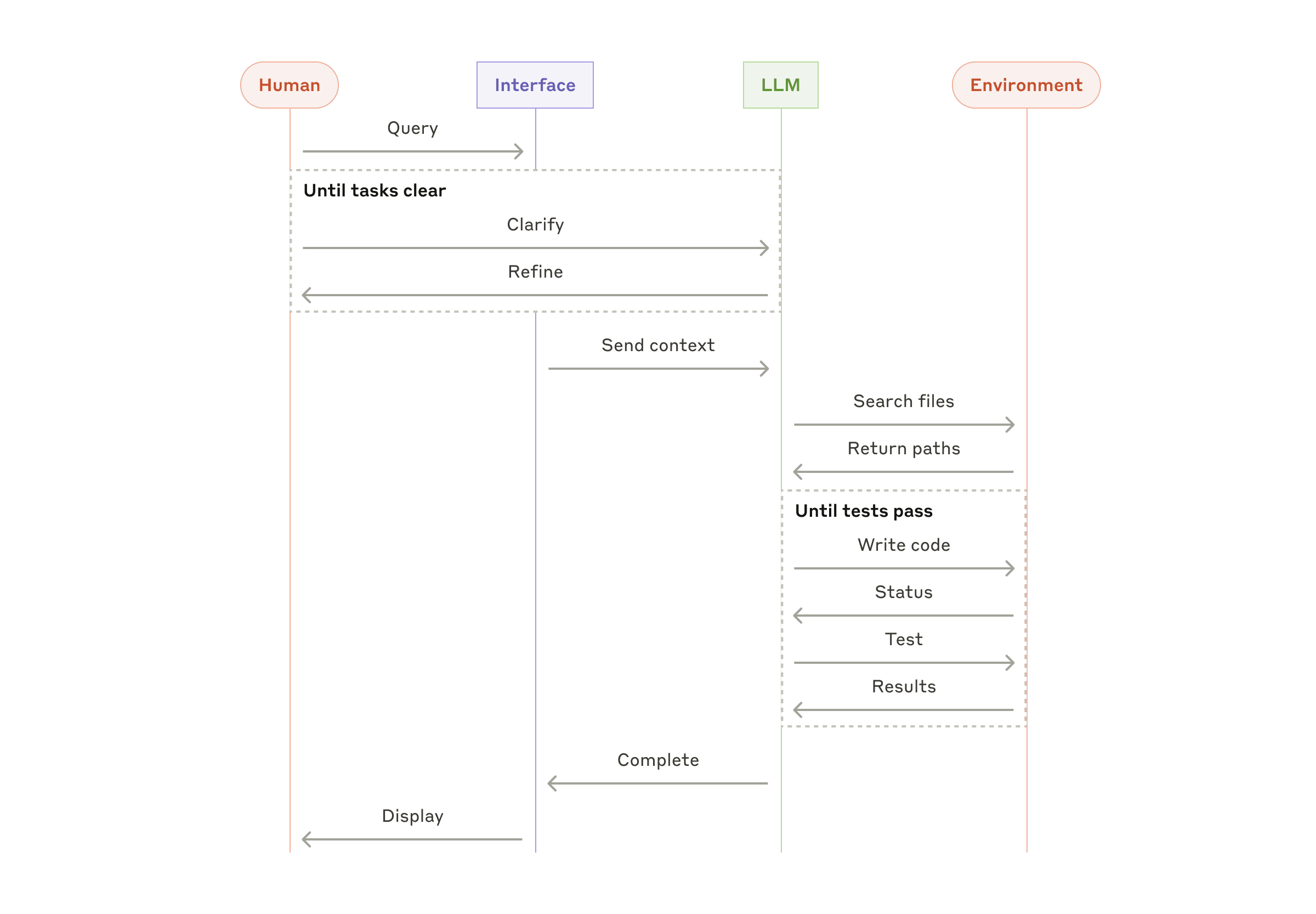
Combining and customizing these patterns
These
Summary
When implementing agents, we try to follow three core principles:
Maintain simplicity in your agent’s design .Prioritize transparency by explicitly showing the agent’s planning steps .Carefully craft your agent-computer interface (ACI) through thorough tool documentation and testing .
Frameworks can help you get started quickly, but don’t hesitate to reduceabstraction layers and build with basic components as you move to production. By following these principles, you can create agents that are not only powerful but also reliable, maintainable, and trusted by their users.
Acknowledgements
Written by Erik Schluntz and Barry Zhang. This work draws upon our experiences building agents at Anthropic and the valuable insights shared by our customers, for which we’re deeply grateful.
Appendix 1: Agents in practice
Our work with customers has revealed two particularly promising applications for AI agents that demonstrate the
A. Customer support
Customer support combines familiar chatbot interfaces with
- Support interactions naturally follow a conversation flow while requiring access to
external information and actions ; - Tools can be integrated to
pull customer data, order history, and knowledge base articles ; - Actions such as
issuing refunds or updating tickets can be handled programmatically; and - Success can be clearly measured through
user-defined resolutions .
Several companies have demonstrated theviability of this approach throughusage-based pricing models that charge only for successful resolutions, showing confidence in their agents’ effectiveness.
B. Coding agents
The software development space has shown remarkable potential for LLM features, with capabilities evolving from code completion to
- Code solutions are
verifiable through automated tests ; - Agents can
iterate on solutions using test results as feedback ; - The problem space is well-defined and structured; and
Output quality can be measured objectively .
In our own implementation, agents can now solve real GitHub issues in the SWE-bench Verified benchmark based on the pull request description alone. However, whereas automated testing helps verify functionality, human review remains crucial for ensuring solutions align with broader system requirements.
Appendix 2: Prompt engineering your tools
No matter which agentic system you’re building, tools will likely be an important part of your agent. Tools enable Claude to interact with
There are often several ways to specify the same action. For instance, you can specify a file edit by writing a diff, or by rewriting the entire file. For structured output, you can return code inside markdown or inside JSON. In software engineering, differences like these are cosmetic and can be converted losslessly from one to the other. However, some formats are much more difficult for an LLM to write than others. Writing a diff requires knowing how many lines are changing in the chunk header before the new code is written. Writing code inside JSON (compared to markdown) requires extra escaping of newlines and quotes.
Our suggestions for deciding on tool formats are the following:
Give the model enough tokens to “think” before it writes itself into a corner .Keep the format close to what the model has seen naturally occurring in text on the internet .Make sure there’s no formatting “overhead” such as having to keep an accurate count of thousands of lines of code, or string-escaping any code it writes .
One rule of thumb is to think about how much effort goes into human-computer interfaces (HCI), and plan to invest just as much effort in creating good agent-computer interfaces (ACI). Here are some thoughts on how to do so:Put yourself in the model’s shoes . Is it obvious how to use this tool, based on the description and parameters, or would you need to think carefully about it? If so, then it’s probably also true for the model. A good tool definition often includes example usage, edge cases, input format requirements, and clear boundaries from other tools.How can you change parameter names or descriptions to make things more obvious? Think of this as writing a great docstring for a junior developer on your team. This is especially important when using many similar tools.Test how the model uses your tools: Run many example inputs in our workbench to see what mistakes the model makes, and iterate .Poka-yoke your tools . Change the arguments so that it is harder to make mistakes.
While building our agent for SWE-bench, we actually spent more time optimizing our tools than the overall prompt. For example, we found that the model would make mistakes with tools using relative filepaths after the agent had moved out of the root directory. To fix this, we changed the tool to always require absolute filepaths—and we found that the model used this method flawlessly.
- 版权声明: 感谢您的阅读,本文由屈定's Blog版权所有。如若转载,请注明出处。
- 文章标题: Building effective agents
- 文章链接: https://mrdear.cn/posts/llm_building_effective_agents