
实践 -- Rome源码阅读
之前写了一篇《读书笔记 – 通用源码阅读指南》,本篇是按照指南教程尝试阅读下Rome这个项目。之所以选择Rome,因为最近想要写一个RSS解析器,了解下面对多种格式有什么比较好的方式能够做到灵活扩展以及使用上的优雅兼存。我大概能够想象到这个工作量不在于难度,而在于多种格式的适配以及扩展性的兼顾,所以想要参考下Rome的实现策略,接下来按照之前定义的步骤开始阅读之旅。
1. 全面了解项目
Rome是一个比较有历史的RSS解析工具,主要提供了以下功能:
- 读取RSS,ATOM
- 输出RSS,ATOM
- 聚合多个RSS或者ATOM,以统一格式输出
- 支持扩展格式解析(module),即可以在解析或者输出过程中增加自定义转换或者标签输出
参考:https://rometools.github.io/rome/HowRomeWorks/index.html
看到这里,不自觉会产生几个问题:
- 如何将全部格式统一?不统一的话,每个格式之间的转换就是笛卡儿积
- 如何判断该使用什么解析器?
- 字段级解析以及输入输出怎么扩展支持?
2. 搭建可调试环境
该项目依赖第三方较少,git拉下来代码后,单测直接可以跑,很方便调试,这里提供一个testcase
1 | public class TestReadWriter extends FeedTest { |
3. 追踪项目的骨架脉络
该项目的核心流程:读取RSS源数据 → 解析成标准格式 → 按照指定格式输出。因此按照上述的testcase,跟踪源代码绘制即可,我的绘制结果如下:
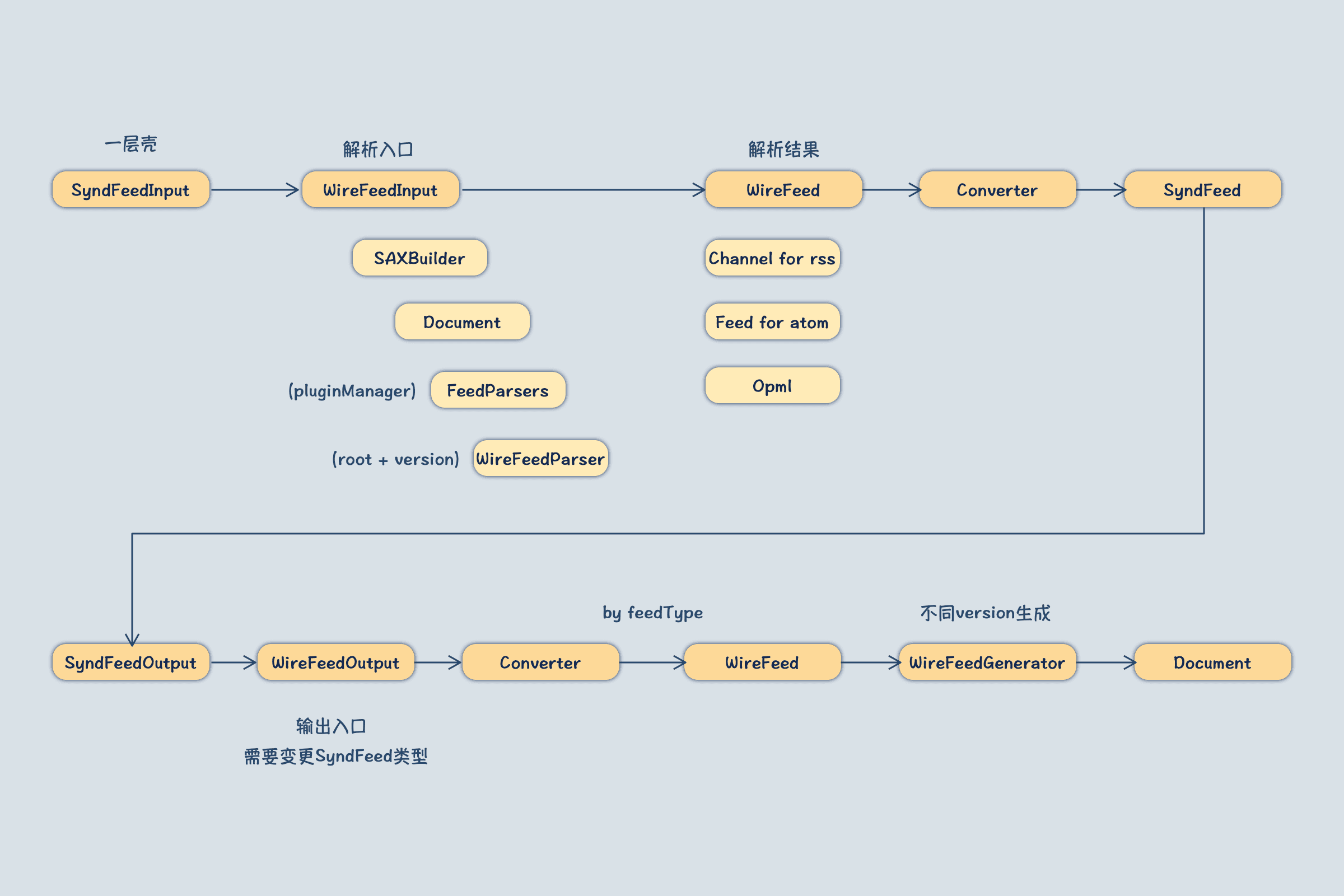
- 依赖JDOM提供的SAXBuilder将XML解析成Document,再通过FeedParser解析成WireFeed类型,该类型为origin类型,存在RSS和ATOM以及OPML不同的实现类。
- 接下来通过Convert将WireFeed转换为SyndFeed,SyndFeed为公共类型抽象,无论底层是rss还是atom都会到这个类型来表示。
- 输出同理,将SyndFeed再转换为WireFeed,此时是需要输出到什么格式,就转换为具体的WireFeed实现类,最后通过WireFeedGenerator输出到XML的Document。
4.将源码的所有包从功能上进行划分
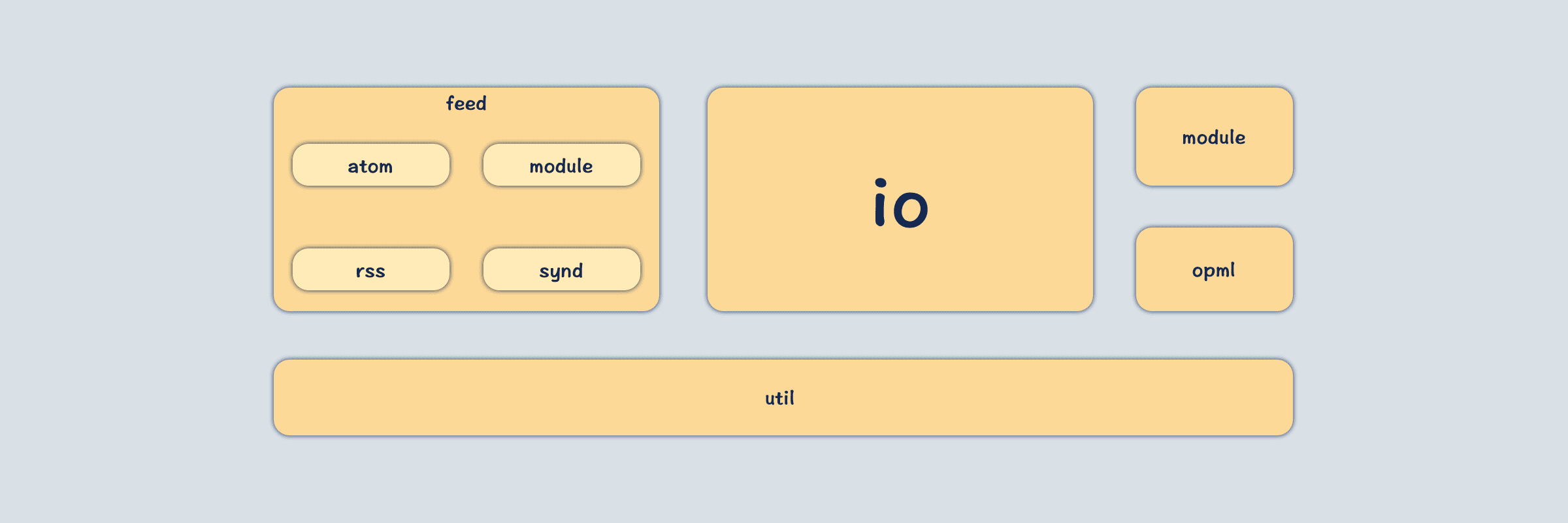
该项目包划分不是很细致,主要有以下几个包:
- util:工具类
- module:利用module能力扩展出来的一些功能支持
- opml:针对opml扩展出来的支持
- io:主要是xml解析以及输出实现,还包含了全局的PluginManager系统
- feed:rss或者atom模型的定义
综合复杂度以及依赖关系:uitl → feed → io → opml → module,因此源码阅读顺序就按照这个来。
util包阅读
该包都是一些简单工具类方法,看了一遍后,略过。
feed包阅读
该包主要是定义实体类模型,比如针对RSS定义了Channel类,针对ATOM定了Feed类,以及公共抽象SyndFeed也都在这个包下面。
impl包
该包是利用反射能力,包装了一套bean clone能力,其核心类有:
- CopyFromHelper:将一个bean的属性,copy到另一个bean上,要求两个类归属一致,并且存在对应的get set方法即可
- CloneableBean:针对一个bean实例提供深拷贝能力,也是get set调用获取以及设置值
- EqualsBean:对比两个bean是否一致,对比实例的每一个属性值
- ToStringBean:输出toString信息
该包这些功能实际上可以单独给封装到另外的包,在feed下面我认为最主要的原因是这些功能都是给feed实体准备的,因为要将不同的格式统一到同一种结构上,那么势必会带来很多属性值copy。
atom & rss包
- WireFeed:真实结构类parent,主要定义当前类型信息,子类有如下两者。
- Feed:描述atom结构的类,都是相对于xml文件,这里会列出所有可能存在元素
- Channel:描述rss结构的类,都是相对于xml文件,这里会列出所有可能存在元素
module包
module在这里使用的并不多,更多的则是接口定义,至于有什么用处,暂时还看不出来,因此这部分遗留到module再处理。这里大致可以看出来,module是根据namespace做出来的扩展,对于一个namespace可以指定module解析,并将结果放入到Feed实例中。
synd包
- SyndFeed:用来统一不同源格式的类,其他源都能够转换到这个类。
- SyndContent:描述文本内容
- SyndLink:描述链接地址
- SyndImage:描述图像
- SyndEntry:描述每一个Item
- SyndEnclosure:描述RSS中媒体元素
- SyndPerson:描述作者
- Element:其他额外元素
- Module:扩展出来的元素
- Converter:用于将原始WireFeed格式与SyndFeed转换的类,针对每一个格式有单独实现
copyInto:将WireFeed转换为SyndFeedcreateRealFeed:将SyndFeed转换为WireFeed
这里第一次碰到了 PluginManager 这个类,这个类类似于策略模式的策略管理器,Converters实现了这个类,从而有了多种Convert的管理能力,因此可以抉择最终使用哪一个Convert。PluginManager的解析,放到接下来的IO包中在看。
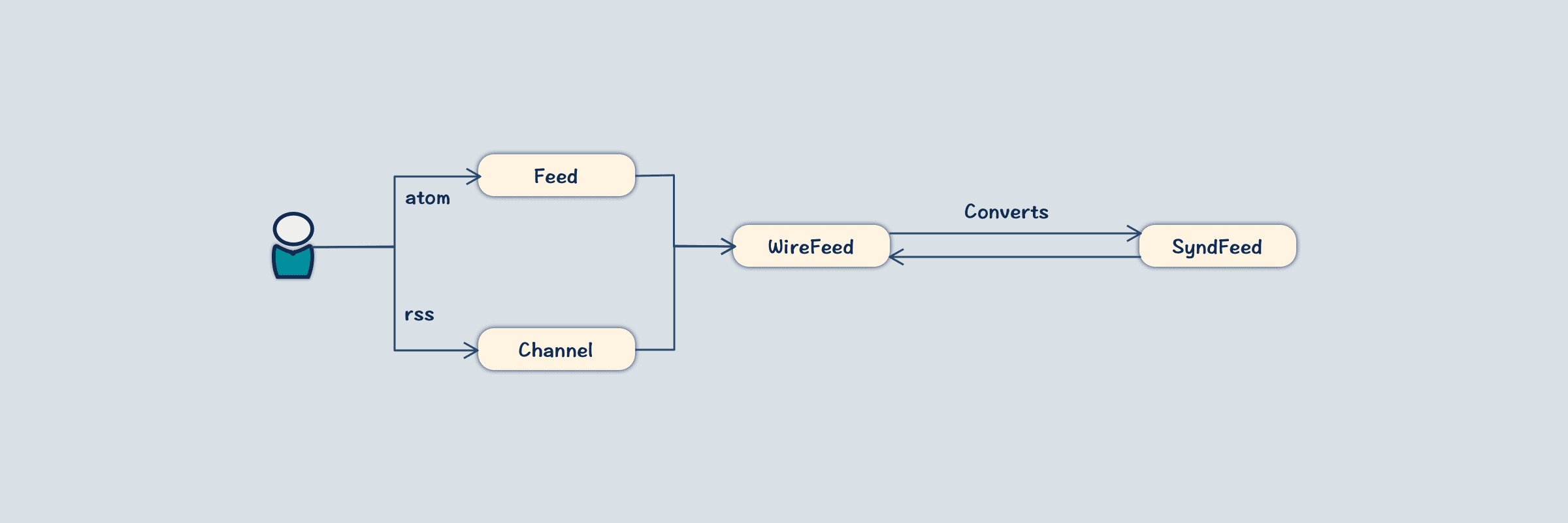
IO包
该包主要定义解析规则,即XML怎么到WireFeed,以及WireFeed又怎么写回RSS,同时还有WireFeed与SyndFeed之间的转换逻辑。
~ xml解析
- XmlFixerReader:包装读取的inputstream
- SAXBuilder:读取上述的inputstream
~ PluginManager加载
PluginManager是类似与Java的serviceload机制写的一套扩展策略管理系统,在配置中存在 rome.properties 配置文件,里面会按照如下指定了涉及到的class全类名,然后PluginManager要做的就是将这些类实例化,管理起来。
至于为什么这样设计?这样设计可以做到很灵活,因为用户也可以自己指定这个配置,来扩展自己想要的解析策略。于现在的做法,我更加倾向于简单点的一个静态Config类来管理这部分的配置。
在OSGI多类加载器下,这样的模式有点问题,用户指定的以及系统自带的可能不是一个类加载器,因此提供了 ConfigurableClassLoader 这个接口,可以指定加载使用的类加载器信息。
1 | Converter.classes=com.rometools.rome.feed.synd.impl.ConverterForAtom10 \ |
~ 解析流程
解析流程还是复用上述代码,主要分析build里面做了哪些事情。
1 | Reader reader = getFeedReader(); |
- SyndFeedInput为入口类,拿到reader后,直接转交给WireFeedInput进行解析。这里是参考了Model的设计。
- WireFeedInput解析后产生的是 WireFeed
- SyndFeedInput则是将 WireFeed 转换为 SyndFeed
- 构建XML解析器:使用的是
SAXBuilder,通过xml解析得到Document实例 - 通过 FeedParsers 得到 WireFeedParser 实例,开始触发解析转换流程
- FeedParsers继承了PluginManager,通过 WireFeedParser.classes 属性key,获取对应的FeedParser实现类。
- WireFeedParser中有一个
boolean isMyType(final Document document)方法,该方法判断一个实例当前是否支持解析,判断依据是root元素,version,namespace等信息。- 以RSS_2.0为例:root元素为
rss,version为2.0,version不存在则默认2.0
- 以RSS_2.0为例:root元素为
- 以rss_2.0解析为例,接下来就是创建Channel,然后分别解析channel以及item,补全该实例
- 解析过程中,会加载module,module也是PluginManager的实现类,通过properties指定。Module分为了 root,channel类型,用于定制不同块的解析,解析后元素统一使用Module顶层类存入List中。
- 使用Converter将WireFeed转换为SyndFeed实例
~ 输出流程
输出指的是针对SyndFeed转换为xml结构。
1 | SyndFeedOutput output = new SyndFeedOutput(); |
- 同样是两层结构,SyndFeedOutput 负责将 SyndFeed 转换为 WireFeed,WireFeedOutput则是负责将WireFeed转换为xml
- SyndFeed到WireFeed,同样是Converter负责转换,这里使用哪一个convert,取决于上述代码中第三行,将当前SyndFeed变更feedType,这个设计我个人觉得很不好,主要是改变原有的SyndFeed内容。
- WireFeed到Document,主要使用WireFeedGenerator,这个类也是有PluginManager管理起来的,因此根据feedType可以直接选定,选定后,按照指定格式构建xml。
opml包阅读
Opml是基于上述体系扩展出来的一个格式支持,与RSS,ATOM同等级。
- feed.opml:定义了opml的属性,其中Opml类继承了WireFeed
- feed.synd.impl:定义了Convert,即WireFeed如何与SyndFeed转换
- feed.io.iml:定义了opml解析以及输出策略类
module包阅读
module的核心是ModuleParser与ModuleGenerator两个类,两者都可以在properties中配置,然后嵌入到xml解析以及输出中,用于定制相关的能力,这里就不详细看了,因为觉得这种定制方式并不是很友好。
总结
首先回答下最初的疑问:
- 如何将全部格式统一?不统一的话,每个格式之间的转换就是笛卡儿积
- 其实格式并不是很多,atom和rss可以使用全集应对,使用顶层类来减少转换的笛卡儿积。
- 如何判断该使用什么解析器?
- root,version,namespace
- 字段级解析以及输入输出怎么扩展支持?
- 没有发现字段级别定制能力,但可以通过module来扩展解析,只不过扩展都都统一存到List结构中,消费使用不方便
Rome的模型结构以及module扩展方式,我个人觉得使用上不是很友好,定制能力也不够强,比如针对时间字段的不同格式使用不同的解析,这个在rome中只能以自定义module来实现,但消费module结果又不那么方便。至于什么样子的既能符合使用上的直觉,有具备很强的定制能力,这个还没想好怎么处理。我的大致思路是将主体保留到实体类中,比如title,author,description,其他字段都以策略枚举的方式扩展出去,这样能够解决扩展性问题,但实用性上还没想好怎么处理,大概思路是定义特定类型访问接口,让策略枚举字段主动支持上述格式的解析。
此外这种通用源码阅读方式,针对这种简单的小项目非常适合,这样的步骤可以轻易将小项目拆解,从而完整的了解到项目全貌。
- 版权声明: 感谢您的阅读,本文由屈定's Blog版权所有。如若转载,请注明出处。
- 文章标题: 实践 -- Rome源码阅读
- 文章链接: https://mrdear.cn/posts/work-read-rome-source