
Netty -- 粘包与半包详解
粘包与半包在中文网络上争议很大,有些人认为这是中式伪概念,对于一个流式协议来说本身没有包概念,何来粘包与半包说法,这种说法是对流式协议理解不到位才会导致这样的翻译,博主认为这样理解也没多大问题,粘包与半包是应用层出现的问题,但不能只揪住这一点,因为该问题确确实实存在,分析清楚然后解决它才是目地。博主希望大家理性看待,少一些争论。
什么是粘包和半包
粘包与半包是应用层协议在对接TCP/IP网络协议时,对所遇到的对接问题定义的概念,所以在使用Netty编写网络通信框架时,这一概念经常被提起。那么什么是粘包和半包问题呢?
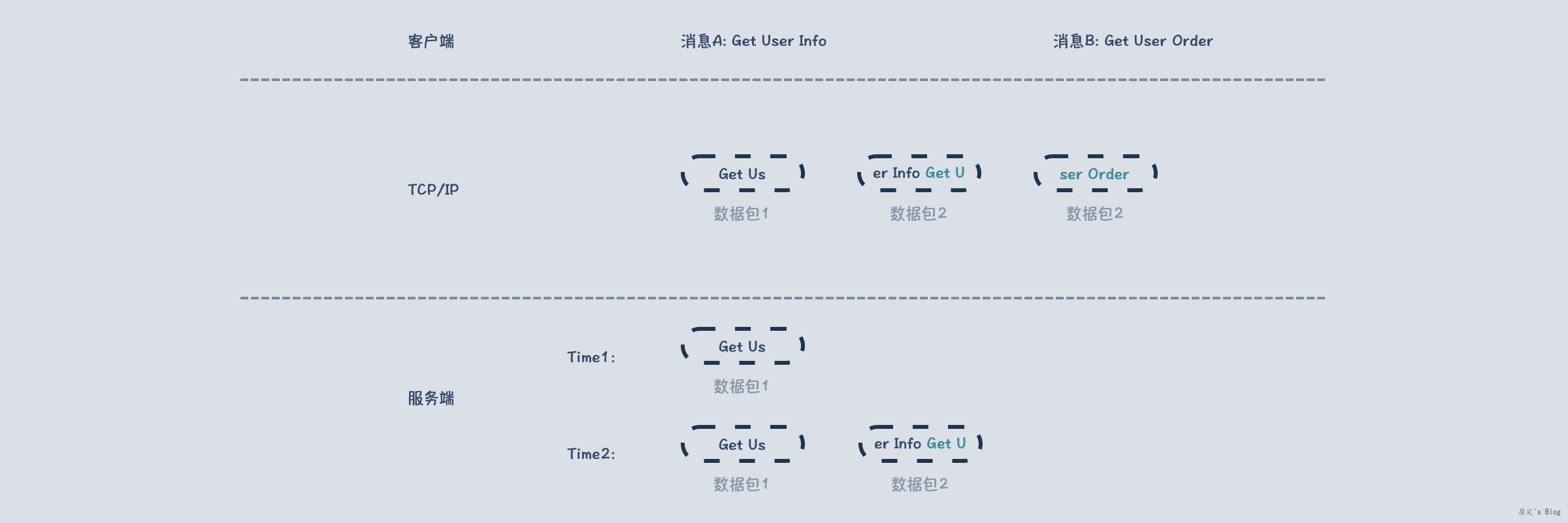
在网络编程中,客户端往服务端发送消息是以消息为单位,TCP/IP传输时,消息会被拆分为多个数据包,该层是以数据包为单位,接着三次握手之后,服务端通过accept()函数获取到该连接,然后开始读取数据,读取的是一个个数据包,此时客户端的消息相当于失真,需要服务端将这些数据包还原成对应的消息,在还原过程中就可能出现如下情况:
在Time1时刻,服务端只拿到了数据包1,此时并不能完整的还原出消息A,这种现象被称为半包,对于服务端的影响是需要判断一个包是否完整,从而才能决定是否反序列化成应用层消息体。
在Time2时刻,服务端又拿到了数据包2,但数据包2中除了消息A还有消息B的部分内容,这种现象称为粘包,对服务端的影响是需要感知消息A的结束,以及消息B的起始位置。
本文接下来会从整个链路角度,来详细解释产生这种问题的本质原因,以及介绍一些经典应用层协议的优秀解法。
TCP/IP协议为什么会粘包/半包?
粘包/半包现象与TCP关联最多,要详细了解产生这类问题的本质原因,需要对整个链路传输情况有个大致的了解,关键点是每个阶段其认为的消息传输最小单位是什么,这个最小单位决定了该层对消息将如何拆分。
应用层传输
应用层是面向业务的一层,以浏览器访问百度为例,会发送如下HTTP协议完整消息,包含起始行,头部,空行(CRLF),实体(payload),那么完整的HTTP协议请求格式是该层认为的最小传输单位。
1 | curl 'https://www.baidu.com/' \ |

TCP层传输
应用层到达TCP层后,TCP并不关心对应的业务,在TCP看来要发送的数据就是一定长度的二进制序列而已。数据提交过来时,会先进入到一个发送缓冲区,而不是立马发送,因为TCP不知道应用层是一次性写入还是分多段写入。那么TCP什么时候开始发送呢?
TCP会根据MSS大小进行判断,MSS到底多大,受限于MTU,MTU表示一个网络包的最大长度,是数据链路层的限制,在网卡处可以设置,路由器处也可以设置,一般为1500字节,MSS是一般为1460 (MTU(1500) - IP头部(20) - TCP头部(20))。
在三次握手时,通讯双方为了最大效率会协商MSS大小,确定最优MSS,一般是最小的一个值,就像木桶效应一样,盛水量取决于最短的一块木板。当TCP收到的数据长度超过或者接近MSS时,再发送数据,避免大量小包问题,从而提高网络效率。
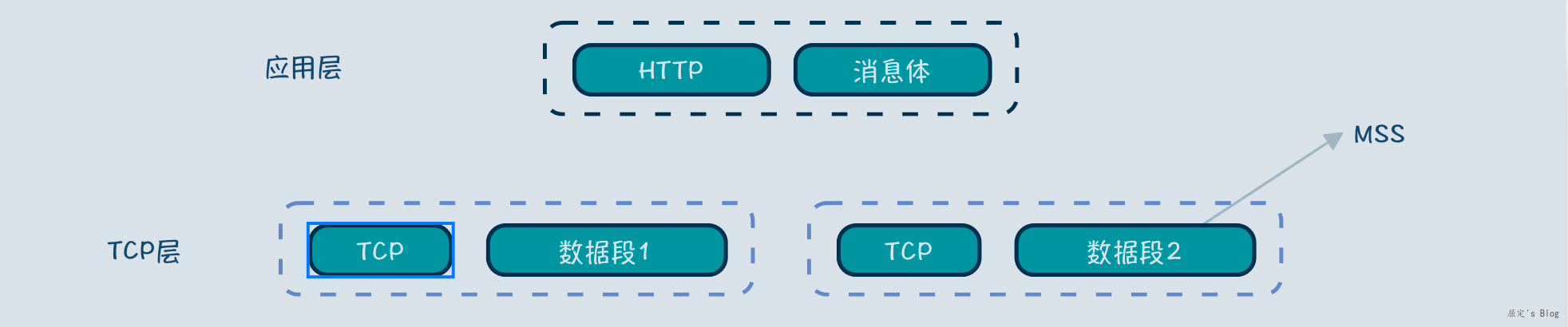
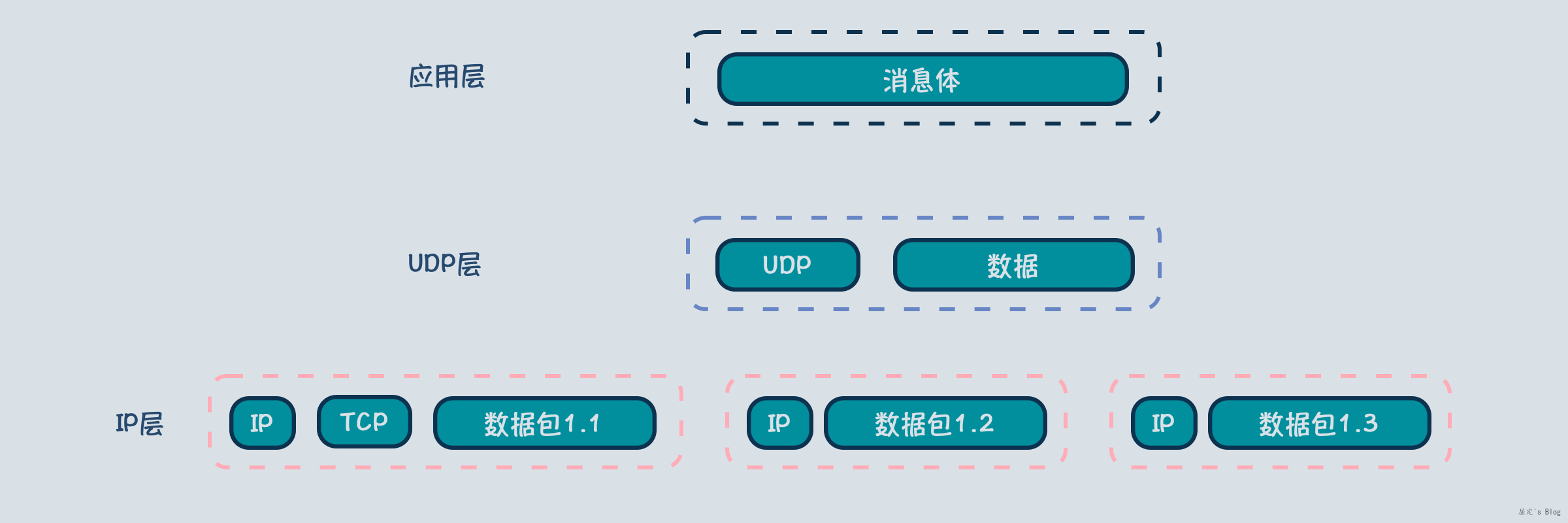
正是因为这样,所以应用层的消息到TCP层后,如下图所示会拆分成多个数据段,每个数据段长度小于或者等于MSS,数据块 + TCP头部,组成了TCP层的数据段,因此数据段是TCP层数据传输的最小单位。
IP层传输
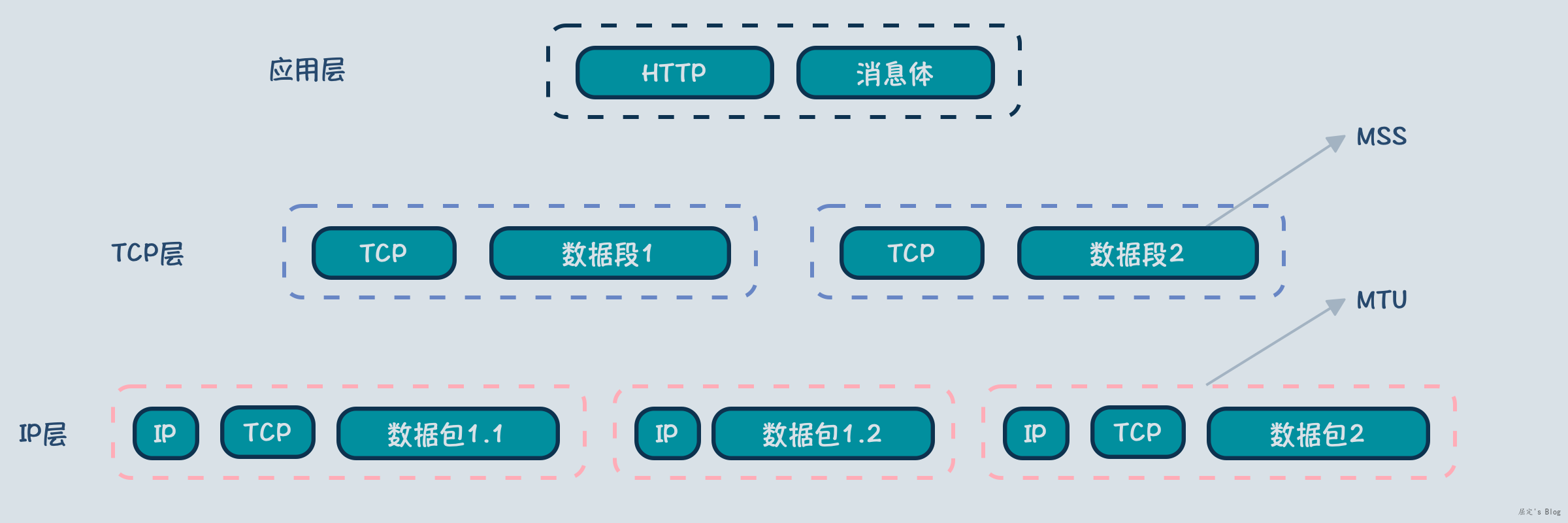
IP层主要与数据链路层打交道,也就是路由器的端口,由于路由器的端口对接不同线路,每个线路最大传输包长度不尽相同,遇到这种情况需要IP层的定义的分片功能对较大的数据段进行拆分。
分片的过程首先是获取MTU,也就是最大网络包长度限制,MTU一般是物理端口支持最大包长度(1518) - MAC头部(14) - 尾部校验+FCS(4) = 1500,知道MTU后,拆包就按照MTU长度拆即可,拆出来的小包不需要有TCP头了,直接附属上IP头即可,如下图所示,数据块1被拆分为数据包1.1和数据包1.2,其中1.2部分只需要IP头部即可,因此数据包是IP层的最小传输单位。
粘包原因以及长连接短连接
经过上面的分析,应用层一个请求传输过程中,会被两次拆分,其中第一次TCP拆分时,通过MSS参数尽量避免IP层而二次拆分,即使IP层数据拆分后,在服务端IP层也会将数据合并起来,完整的将数据段交给TCP层,然后转交给应用层,那么粘包与半包自然而然就是TCP分段传输带来的问题了。
具体分析半包,半包是由于应用层数据太大,到TCP层后会被分段传输,到达服务端,应用层看到的是一段一段的数据,此时需要服务端等待全部数据到达后,才能还原出具体的应用层消息,也因此无论长连接还是短连接,都会出现半包问题。
具体分析粘包,粘包的发生是因为应用层使用同一个TCP连接传输了消息A和消息B,也就是长连接情况下会发生的问题,长连接下,TCP通道会被复用,顺序传输多次请求,由于TCP发送缓存队列存在,就会导致两个请求在一个数据段中。短链接情况下,每一次建立连接只会传输一个请求,传输完毕就关闭连接,这种情况下自然不存在粘包现象。
UDP/IP为什么不会粘包?
UDP是仅仅是为了传输开发的协议,UDP在接收到应用层消息体后,是直接将全部消息体丢给IP层,依赖IP层的分片,自身传输仍然是以消息为单位,那么服务端接收到的自然也是IP层重组合并之后的消息,因此不会出现粘包以及半包现象。
粘包与半包常见解决方案
TCP只是在保证可靠性的前提下,尽可能提高网络利用率,粘包与半包是应用层需要解决的问题,解决方案的主要思路是增加消息边界描述,应用层在解析时能够感知到消息边界,具体做法则有很多黑科技可以讨论了,接下来分析下一些主流协议使用的解决方案。
HTTP/1.1
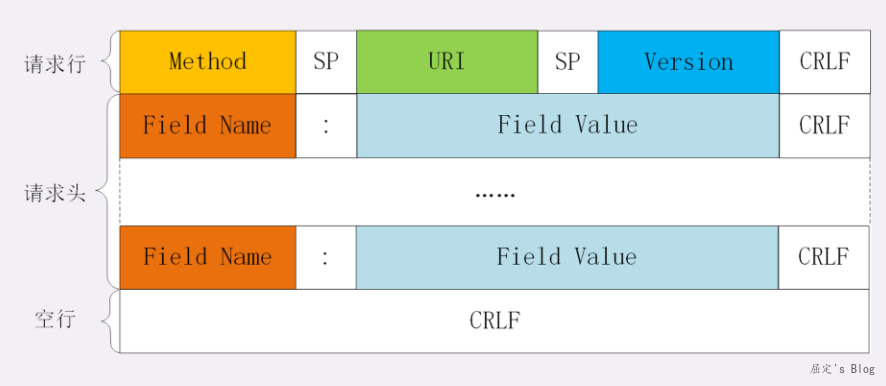
HTTP/1.1目前仍然在广泛使用,在HTTP/1.1当中,开启keep-alive后,TCP连接会被复用,也就是长连接,此时粘包和半包问题都会出现,为了解决类似问题,HTTP对于消息格式有一个强制性要求,借用极客时间的图,第一行是请求行,三个字段使用空格分割,以CRLF结尾,中间部分是请求头,以:号分割,CRLF结尾,以单独一个空行CRLF标识请求头结束,接着是请求体内容。
服务端解析时,针对请求行和请求头则逐个字节扫描,当发现是LF标识结尾时,即可解析已读取内容,当检测到CRLF之后又一个CRLF则标识请求头解析完毕,接着解析请求体。请求体解析有两种形式,第一种是已知请求体长度,在表单请求中比较常见,其会在Header中声明Content-Length,服务端根据该字段确定接下来再读取多少个字节作为请求体。第二种是不知道请求体长度,比如文件上传,HTTP提供了Transfer-Encoding: chunked这一header标识,开启之后,HTTP会分块传输数据,每一块大小是指定的,终止块是一个长度为0的块。有了这些标准,在粘包以及半包情况下,服务端就知道是该拆分还是该等待。
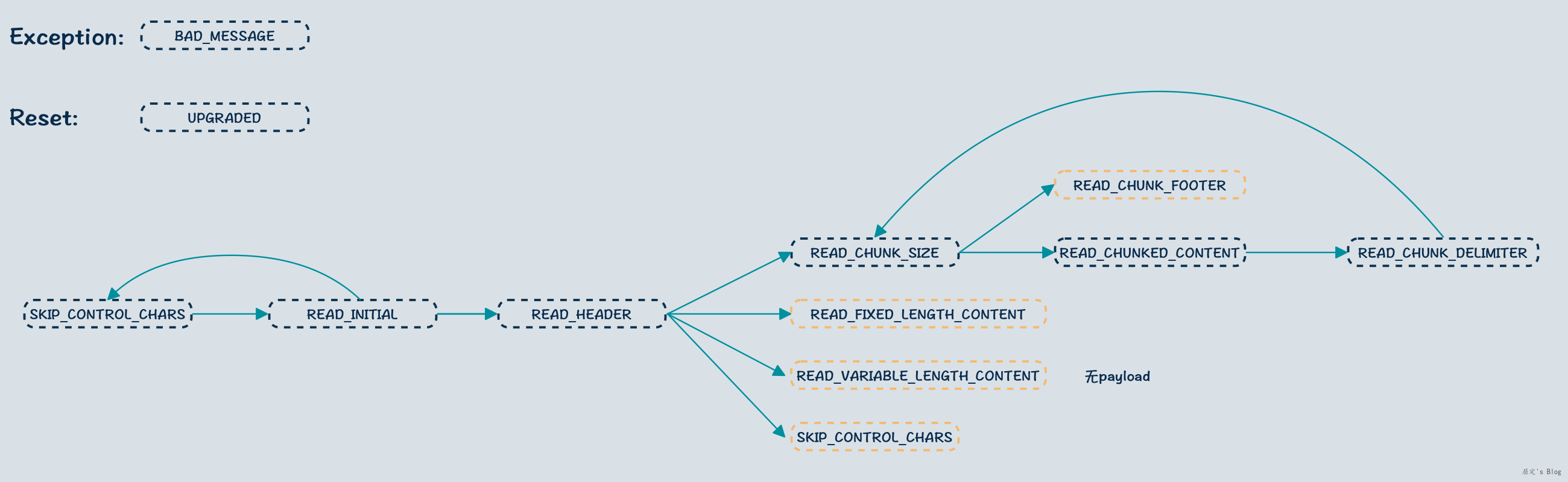
举个实际案例,在Netty的io.netty.handler.codec.http.HttpObjectDecoder中,Netty定义了一套状态机流转方式来解析HTTP消息,博主画了一个图,基本模式就是先读取请求行,然后解析请求头,在解析请求头的过程中,判断接下来状态是读取payload还是直接结束,其中黄色框的读取完后,会重置状态,解析下一个HTTP消息,有兴趣的可以翻阅相关源代码查阅。
简单总结一下,本质上还是使用那个CRLF这一特殊标识定义了消息在各种状态的结束符号,服务端在解析流程中,根据结束符号进行状态流转。
HTTP/2.0
HTTP/2.0相比1.1版本,增加了HTTP连接的多路复用,怎么理解呢?在HTTP1.1时期,虽然有keep-alive机制的长连接,但浏览器在获取一个资源时,会独占一个HTTP请求,只有当该资源获取完毕后,该HTTP才能给其他的资源获取使用。但是HTTP2.0时代,一个HTTP请求可以同时获取多个资源,HTTP层面资源不再排队等待,极大的提升了网络利用率。在这种模式下,HTTP协议是怎么解决粘包和半包问题的呢?
在HTTP2中为了支持多路复用,引入了Stream Frame这一结构,当多个HTTP请求使用同一个连接时,HTTP2会给每一个请求分配一个ID,然后将请求数据包装成一个个Stream Frame,丢给TCP连接传输。对于服务端,同一个HTTP请求的数据还是顺序传输的,当接收到一个Stream Frame后,根据头部的Length判断该包的大小,当读取结束时,开始进行整个包的解析。
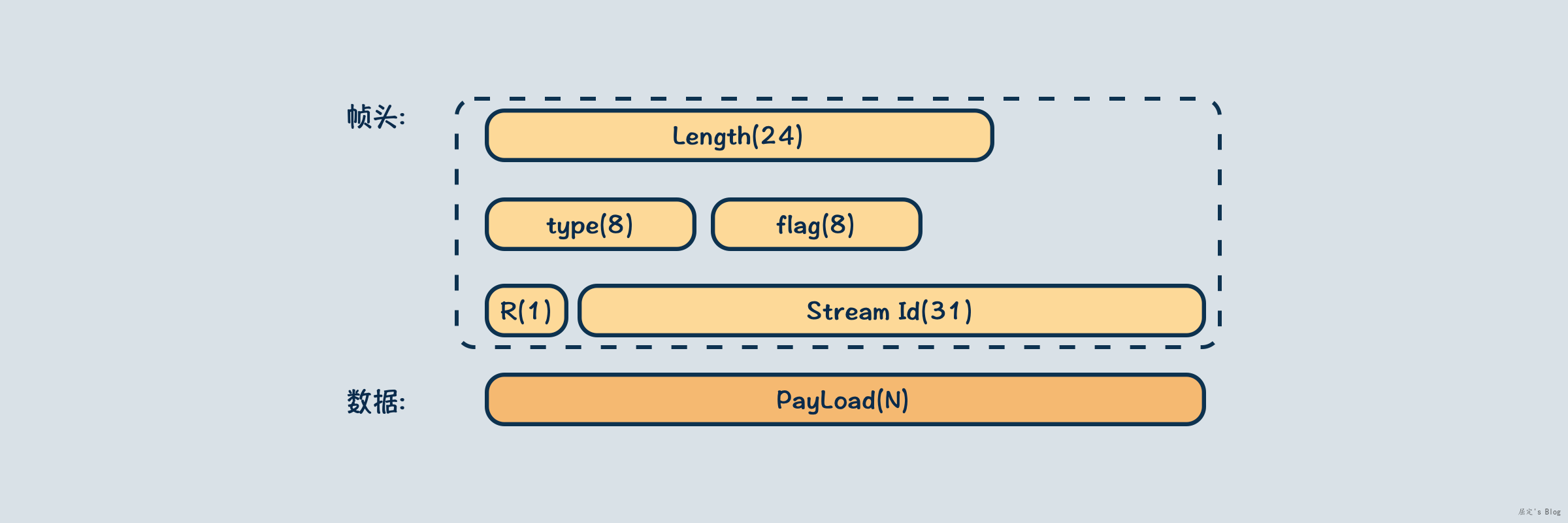
那么还有个问题,怎么判断一个HTTP请求数据发送完毕了呢?该问题分为两部分,一是解析Header结束,二是整个请求结束,针对这种情况,Stream Frame的flag属性针对Header结束定义了END_HEADERS标识,针对整个流则特别定义了一个END_STREAM,因此服务端根据flag标识,能够确定下一步是该读取payload还是结束数据解析。
也简单总结下,因为是定长结构,处理简单了许多,当半包出现时,等就好了,当粘包出现时,因为长度存在也不会导致读错包,服务端接收到多个Stream Frame后,按照id将对应请求的数据进行合并,当接收到结束帧时,完成整个HTTP请求解析,应用链路可以继续往下调用进行。
总结
实际上只要基于TCP/IP实现应用层协议,不可避免的都会遇到应用层数据被拆分现象,粘包与半包的概念提出是为了解决这个问题,让人比较容易理解,我倒是觉得这两个词相当形象得描绘了这一问题,没必要过度反感与抵制。
- 版权声明: 感谢您的阅读,本文由屈定's Blog版权所有。如若转载,请注明出处。
- 文章标题: Netty -- 粘包与半包详解
- 文章链接: https://mrdear.cn/posts/framework-netty-half-packet