
实践 -- 二进制与位运算案例
二进制以及位运算在编程中很少被使用到,但往往使用到的地方都是很巧妙的设计,本文列举了常见的二进制使用案例,希望对你编程设计有所启发。
二进制操作
无论什么语言,二进制操作一般都支持以下指令:
- 按位与
- 按位或
- 左移
- 右移(带符号/不带符号)
以下案例均是这些操作的组合。
枚举类包含与非包含
枚举场景下,使用二进制能够快速判断当前对象是否拥有该枚举状态,举个例子:
1 | enum |
当判断用户是否有哪几个权限时,使用X & U = X,其中X代表要判断的权限,U代表用户当前权限,举个例子:
1 | 判断小明是否拥有B:2 & 3 = 2 拥有 |
该案例引申下,可以在任意有限数据基础上判断包含以及不包含,解决相应业务问题。
分布式ID生成
分布式ID,即在分布式系统下生成不重复且有序增长的ID序列。已Snowflake算法为例,该算法将64个bit位的Long类型数据进行拆分。首位是符号位,不用,中间41位时间戳,接着是10位的机器id,最后是12位序列号,因此每毫秒最大能产生2的12次方,即4096个序列号。
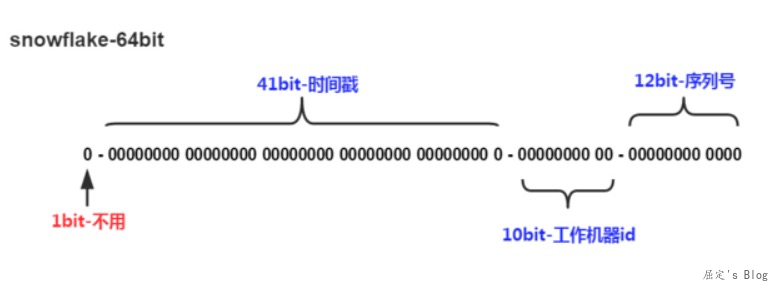
那么回到二进制上,对应bit位的数据该怎么填充?这里填充的实现主要依赖与位移操作。举个例子:
1 | 时间戳:1000000000 (1597996131000-1596996131000) |
使用位移以及|操作完成了数据的拼接。这种想法除了分布式ID外,也可以在业务中很高性能的生成各种ID。博主曾经在设计事件系统ID生成逻辑时,使用过类似方案:1bits + 8bits(ip最后一位) + 12bits(事件码编号) + 2bits(时戳类型,毫秒,秒,分钟) + 41bits(时间戳,简单去重可自定义),因为系统压力不大,所以去重也不需要考虑很复杂,可以说很实用了。
Java ReentrantReadWriteLock设计
Java的ReentrantReadWriteLock是一个可重入读写锁,即写锁,读锁可以多次被获取,且拥有读读不互斥,读写互斥,写写互斥等特性,实现这些特性则需要标记当前写锁获取次数,读锁获取次数。JDK在这里的实现巧妙的使用了32位INT类型数据,其中高16位标识读写数量,低16位标识写锁数量。比如下图,由于写锁存在,所以必然有一个线程获取到了该锁,并且写锁重入2次,读锁也被获取,且重入1次。

按照这种形式定下来后,JDK需要提供一些快速执行四则运算的方法,如下所示,位移以及位运算结合。
1 | int state = xxx ,标识当前锁状态 |
JDK线程池里面也有类似做法,这种有点黑科技的感觉,业务代码还是不要学习这种写法,业务追求的是简单,好理解。
Bloom Filter
Bloom Filter是利用二进制0,1两个真假属性来判断对应值是否包含的一种策略。以下图为例,key1经过三个不同hash函数(f,g,h)分别映射到三个bit槽,key2同样也是。因为hash冲突以及计算bit槽时取余操作,所以Bloom Filter存在不一定真的存在,但不存在则一定不存在,利用该特性可以实现白名单,黑名单等业务需求,并且存在判断也可以作为一些底层存储的前置拦截,减少穿透请求。

不过这些都不是今天讨论的内容,Bloom Filter给二进制操作上带来的问题是如何构造超长的bit位?这个需要我们了解下。
JDK BitSet
JDK的做法使用long[]数组来标识bit set,每一个long位64个bit位,那么一个BitSet初始化后,就是N*64长度,通过取余定操作可以先定位到对应long位置,然后再使用位运算修改bit位。
Redis BitMap
Redis与Java实现类似,不过内部使用的是char[]数组,在C语言中一个char占一个字节,相当于8bit。每一段变小,会造成全遍历统计时数据量庞大,比如统计一共多少个1,Redis在此基础上做了个优化,将对应char[]数组分组,加入128个char一组进行遍历,大大提高了统计效率。
上述两种做法一般应对于数据经常变化的场景,因为要涉及旧数据的更新操作,不过当使用场景下数据比较稀疏时,还是会造成内存的浪费,因此使用时合理选择映射到bit位的id能够节省不少内存消耗。
倒排索引
倒排索引中,倒排表一般会使用跳表或者bitset实现,这里只分析bitset实现方式遇到的挑战以及解法。以ElasticSearch为例,当倒排索引建立后,假设结构如下所示:其中termA,termB,termC为分词之后的词典表,倒排表0则代表当前id不存在,1则代表存在,因此termA有文档4,5,6,7;termB有文档1,2;termC有文档1,4,5。
1 | termA :[0,0,0,1,1,1,1] |
那么要解决的第一个问题,数据怎么存?
倒排索引不同与上述Bloom Filter场景,在ES中数据往往是以亿位单位的,因此倒排表会非常大,倒排词典数据量一多,磁盘占用就会飞速上涨,另外ES底层使用的Luence是写入后不再变更,也就不存在更新场景,因此使得数据压缩有了很好的前置条件。
压缩的思路很简单,100个0存储(100,0)即可,而不是真实的存储100个0。Luence在存储中,使用的是位图压缩结构(Roaring Bitmap)来实现优化。如下图所示:
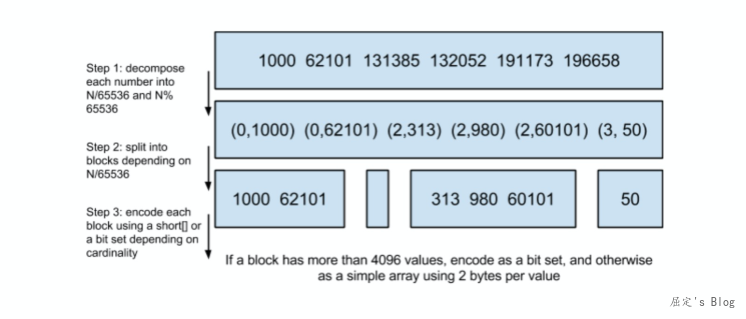
如上图所示这一结构以65536为一块区域,进行分块存储,每一块最多标识65536个文档,当文档数小于4096时,Lucene会使用short[]数组存储,short占的空间:2bytes(65535 = 2^16-1 是2bytes 能表示的最大数),当超过4096时,则使用bitmap 占的空间: 65536/8 = 8192bytes,换句话说一个块最大占用内存8192bytes,也就是8kb。
同样一亿数据量,bitmap结构,必须保存1亿个bit位,但往往这一亿中存在大量不命中的文档id,也就是存在很多个0,此时该算法就能起到很好的压缩效果了。
第二个问题是快速取交集,由于是倒排表是对齐的bit操作,因此可以直接使用&|指令快速求的交集或者并集。
总结
以上内容是对工作至今遇到的案例进行总结,如有错误或者遗漏,欢迎留言指正。
- 版权声明: 感谢您的阅读,本文由屈定's Blog版权所有。如若转载,请注明出处。
- 文章标题: 实践 -- 二进制与位运算案例
- 文章链接: https://mrdear.cn/posts/work-design-binary